Getting started with PySpark 🦆


Apache Spark initially gained traction as part of the Hadoop Stack to run on top of Hadoop Clusters and provide data transformation, but soon Apache Spark was seen as an alternative in itself for processing of Big Data streams. Apache Spark provides a multi language unified engine for large scale data analytics. It can run on top of Hadoop, Cassandra, Mesos, HBase, Hive etc, or even as a standalone cluster.
Core Concepts
Before diving deep into how Apache Spark works, lets understand the jargon of Apache Spark
- Job: A piece of code which reads some input from HDFS or local, performs some computation on the data and writes some output data.
- Stages: Jobs are divided into stages. Stages are classified as a Map or reduce stages (Its easier to understand if you have worked on Hadoop and want to correlate). Stages are divided based on computational boundaries, all computations (operators) cannot be Updated in a single Stage. It happens over many stages.
- Tasks: Each stage has some tasks, one task per partition. One task is executed on one partition of data on one executor (machine).
- DAG: DAG stands for Directed Acyclic Graph, in the present context its a DAG of operators.
- Executor: The process responsible for executing a task.
- Master: The machine on which the Driver program runs
- Slave: The machine on which the Executor program runs
Spark Components
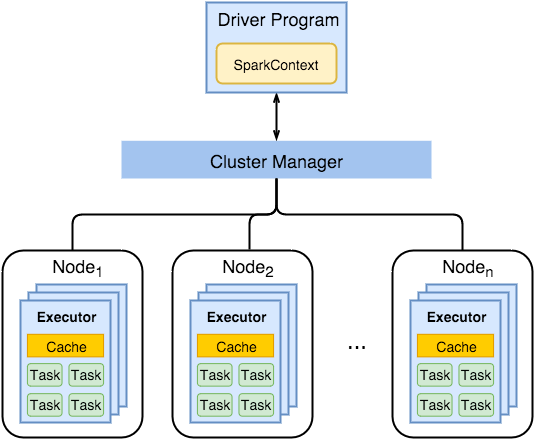
Spark Driver
- separate process to execute user applications
- creates SparkContext to schedule jobs execution and negotiate with cluster manager
Executors
- run tasks scheduled by driver
- store computation results in memory, on disk or off-heap
- interact with storage systems
Cluster Manager
- Mesos
- Hadoop
- Spark Standalone
Spark Driver contains more components responsible for translation of user code into actual jobs executed on cluster:
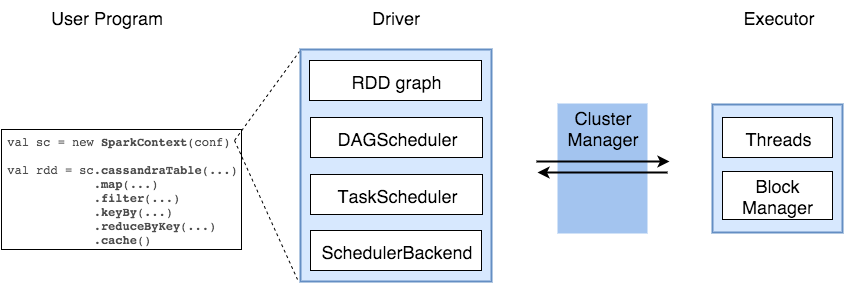
SparkContext represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster
DAGScheduler computes a DAG of stages for each job and submits them to TaskScheduler determines preferred locations for tasks (based on cache status or shuffle files locations) and finds minimum schedule to run the jobs
TaskScheduler responsible for sending tasks to the cluster, running them, retrying if there are failures, and mitigating stragglers
SchedulerBackend backend interface for scheduling systems that allows plugging in different implementations(Mesos, YARN, Hadoop, Standalone, local)
BlockManager provides interfaces for putting and retrieving blocks both locally and remotely into various stores (memory, disk, and off-heap)
Architecture
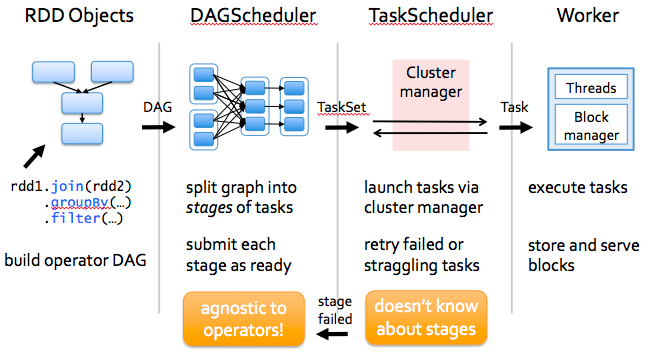
How Spark Works?
Spark has a small code base and the system is divided in various layers. Each layer has some responsibilities. The layers are independent of each other.
The first layer is the interpreter, Spark uses a Scala interpreter, with some modifications. As you enter your code in spark console (creating RDD’s and applying operators), Spark creates a operator graph. When the user runs an action (like collect), the Graph is submitted to a DAG Scheduler. The DAG scheduler divides operator graph into (map and reduce) stages. A stage is comprised of tasks based on partitions of the input data. The DAG scheduler pipelines operators together to optimize the graph. For e.g. Many map operators can be scheduled in a single stage. This optimization is key to Sparks performance. The final result of a DAG scheduler is a set of stages. The stages are passed on to the Task Scheduler. The task scheduler launches tasks via cluster manager. (Spark Standalone/Yarn/Mesos). The task scheduler doesn’t know about dependencies among stages.
Spark in Production
We are well into the Big Data era, with organizations collecting massive amounts of data on a continual basis. Yet, the value of this data deluge hinges on the ability to extract actionable insights in a timely fashion. Hence, there is an increasing need for continuous applications that can derive real-time actionable insights from massive data ingestion pipelines.
However, building production-grade continuous applications can be challenging, as developers need to overcome many obstacles, including:
- Providing end-to-end reliability and correctness guarantees: Long running data processing systems must be resilient to failures by ensuring that outputs are consistent with results processed in batch. Additionally, unusual activities (e.g failures in upstream components, traffic spikes, etc.) must be continuously monitored and automatically mitigated to ensure highly available insights are delivered in real-time.
- Performing complex transformations: Data arrives in a myriad formats (CSV, JSON, Avro, etc.) that often must be restructured, transformed and augmented before being consumed. Such restructuring requires that all the traditional tools from batch processing systems are available, but without the added latencies that they typically entail.
- Handling late or out-of-order data: When dealing with the physical world, data arriving late or out-of-order is a fact of life. As a result, aggregations and other complex computations must be continuously (and accurately) revised as new information arrives.
- Integrating with other systems: Information originates from a variety of sources (Kafka, HDFS, S3, etc), which must be integrated to see the complete picture.
Multi-Language Support
Apache Spark is originally written in Scala and provides support for various languages:
- Scala
- Java
- Python
- SQL
- R
We will be discussing the python flavor of Spark known as PySpark. PySpark provides the flexibility and support of python with power of Spark. PySpark supports all basic ETL operations that is generally done in Pandas. It works as an interface with Resilient Distributed Datasets (RDDs) in Apache Spark and Python programming language
Why to use PySpark over Pandas ?
Both are meant to solve similar problems under different scenarios
Pandas is widely popular in python community . Inbuilt support for numpy is a big advantage for Pandas. It is written in Python and Cython and hence has best of both worlds of high level and low level language.
Benefits of Pandas:
- Projection - creating subset of dataset df['Age, 'Name']
- Filtering - On rows instead of column df[df['Age]>21]
- Joins
- Concatenation
- Aggregations
Eager Execution: Pandas uses something called eager execution and any transformation to DataFrame is performed immediately. Though it's good thing to have results right away while in development mode, this hurts the performance badly in production.
Benefits of PySpark:
Apart from providing out of the box benefits that Pandas provides, PySpark uses lazy execution like traditional SQL languages and hence delays the execution by forming a pipeline of events from the event tree and finally performs the operations at a later stage.
Tensorflow uses both and advices to use eager execution only for the time of development
Drawbacks of Pandas
Processing: Pandas is single threaded and Dask tries to overcome this by reimplementing the Pandas API.
Scalability: Pandas requires all data to fit into the memory. It can not use local hard disk or distributed cluster for processing data
How PySpark overcomes Pandas drawbacks.
Spark was mainly focused at providing better alternate to Hadoop MapReduce. It is built to scale with number of rows and not columns. Hence rows and columns can not be used interchangeably, unlike pandas, but that gives it the power to scale processing and transformation to a very large amount of data. Spark supports nested schema which is the first choice for data in JSON and Avro formats.
In contrast to Pandas, Spark uses a lazy execution model. This means that when you apply some transformation to a DataFrame, the data is not processed immediately. Instead your transformation is recorded in a logical execution plan, which essentially is a graph where nodes represent operations (like reading data or applying a transformation). Spark then will start to work, when the result of all transformation is required — for example when you want to display some records on the console or when you write the results into a file.
Internally Spark uses the following stages:
- A logical execution plan is created from the transformations specified by the developer
- Then an analyzed execution plan is derived where all column names and external references to data sources are checked and resolved
- This plan then is transformed into an optimized execution plan by iteratively applying available optimization strategies. For example filter operations are pushed as near as possible to the data sources in order to reduce the number of records as early as possible. But there are many more optimizations.
- Finally the result of the previous step is transformed into a physical execution plan where transformations are pipelined together into so called stages.
Just to be complete, the physical execution plan then is split up along the data into so called tasks, which then can be executed in parallel and distributed by the machines in the cluster.
Spark also scales very well with huge amounts of data. It does not only scale via multiple machines in a cluster, but the ability to spill intermediate results to disk is at the core of the design of Spark. Therefore Spark is almost never limited by the total amount of main memory, but only by the total amount of available disk space.
Below is a Colab which uses PySpark for processing and model generation
Conclusion
Like Pandas, Spark is a very versatile tool for manipulating large amounts of data. While Pandas surpasses Spark at its reshaping capabilities, Spark excels at working with really huge data sets by making use of disk space in addition to RAM and by scaling to multiple CPU cores, multiple processes and multiple machines in a cluster.
As long as your data has a fixed schema (i.e. no new columns are added every day), Spark will be able to handle it, even if it contains hundreds of billions of rows. This scalability together with the availability of connectors to almost any storage system (i.e. remote filesystem, databases, etc) make Spark a wonderful tool for Big Data engineering and data integration tasks.