System Design - Consistent Hashing


Distributed systems help applications scale and respond to increasing traffic and load. I wrote about CAP theorem in one of my blog which defines the strategy to build highly available and scalable systems and Partitioning is one of the major design decisions. But horizontal scaling does come with its own caveats. To ensure that the system runs with predictable performance we must ensure that data is distributed evenly and rightfully (In cases with Servers of different capacity, load should be distributed as per the server capacity) . Also in large systems the load keeps on changing and hence the total count of servers keeps on changing. A new server(s) might get added or removed every now and then.
Simple Hashing
To distribute the data evenly across servers a traditional hashing algorithm is used such as md5.
serverIndex = hash(objectKey) % N // N is size of server pool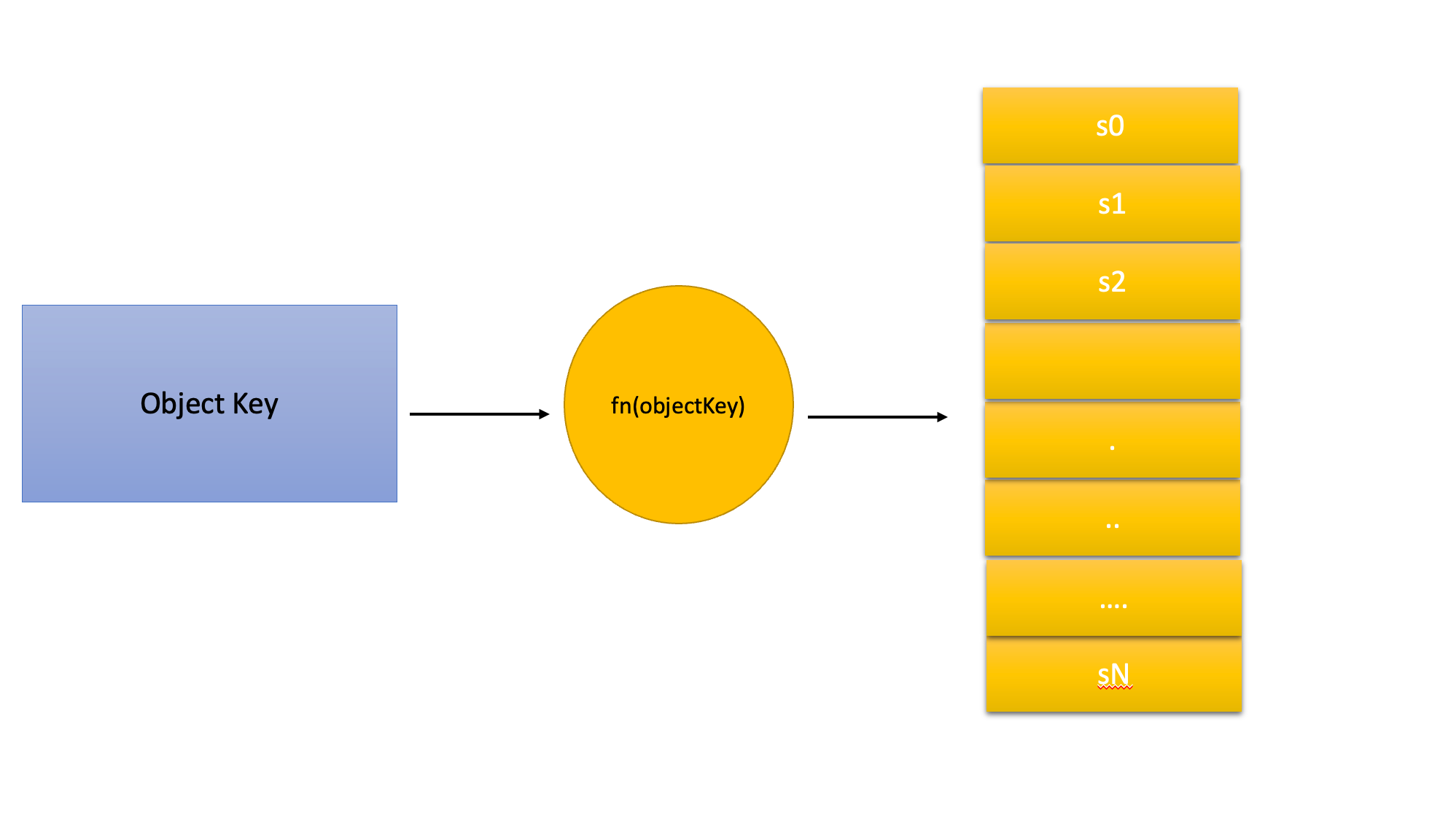
As long as the count of servers remains the same an object key is always mapped to the same server.
This approach works fine until the size of the s
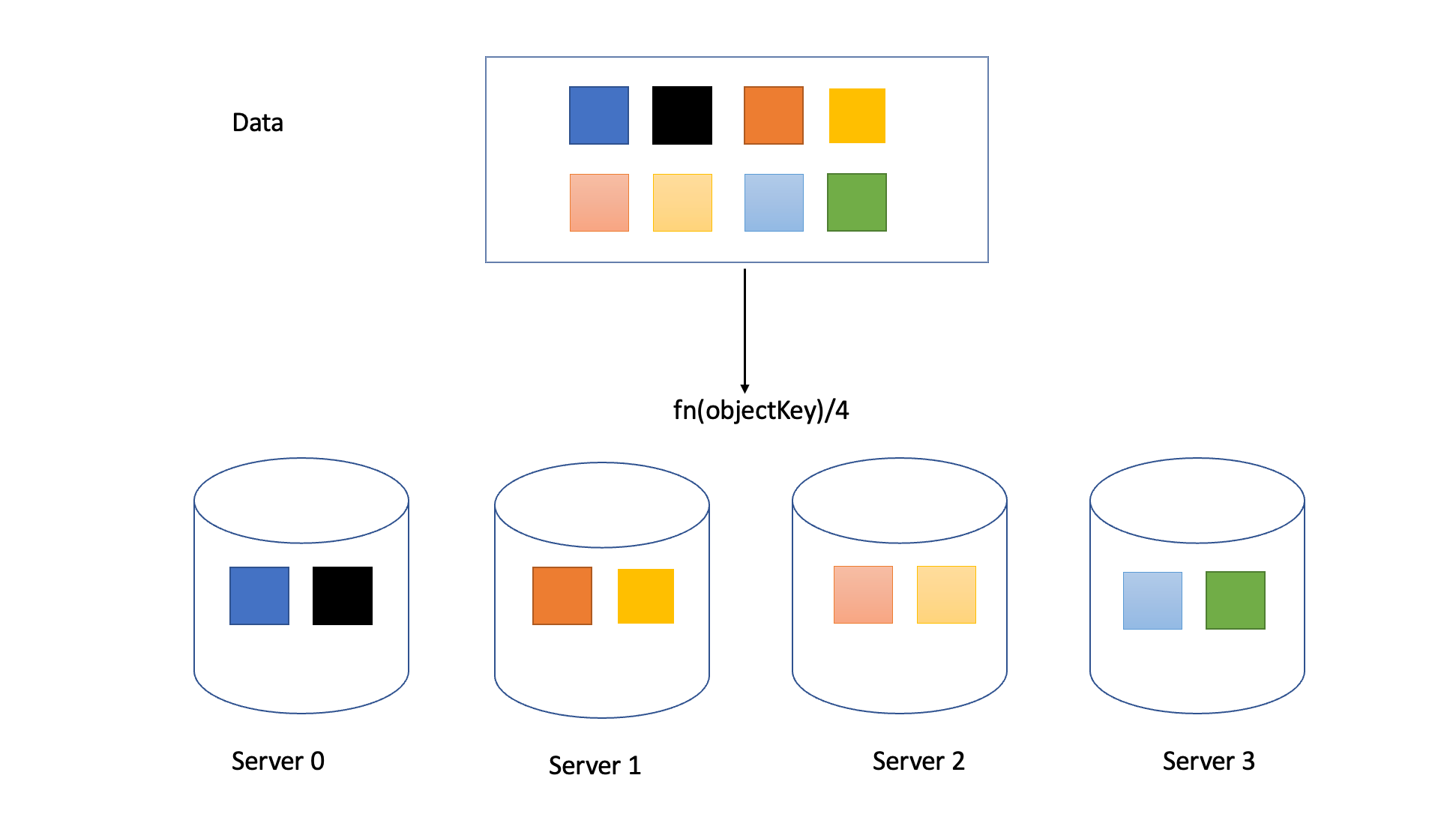
But when we need to remove a server for failure or because of continuous lower load (Same thing will happen in case of addition of a new server for higher load)
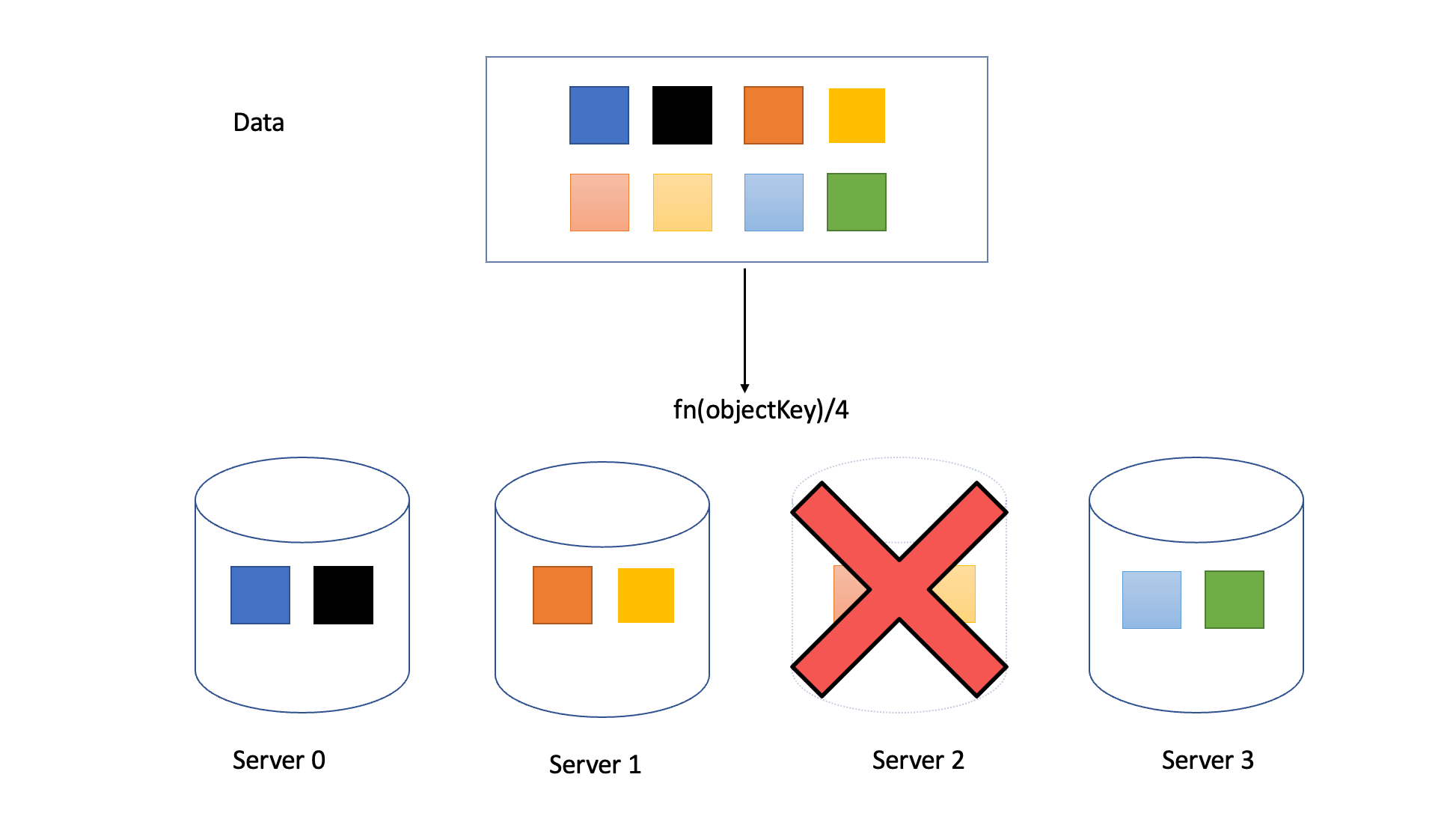
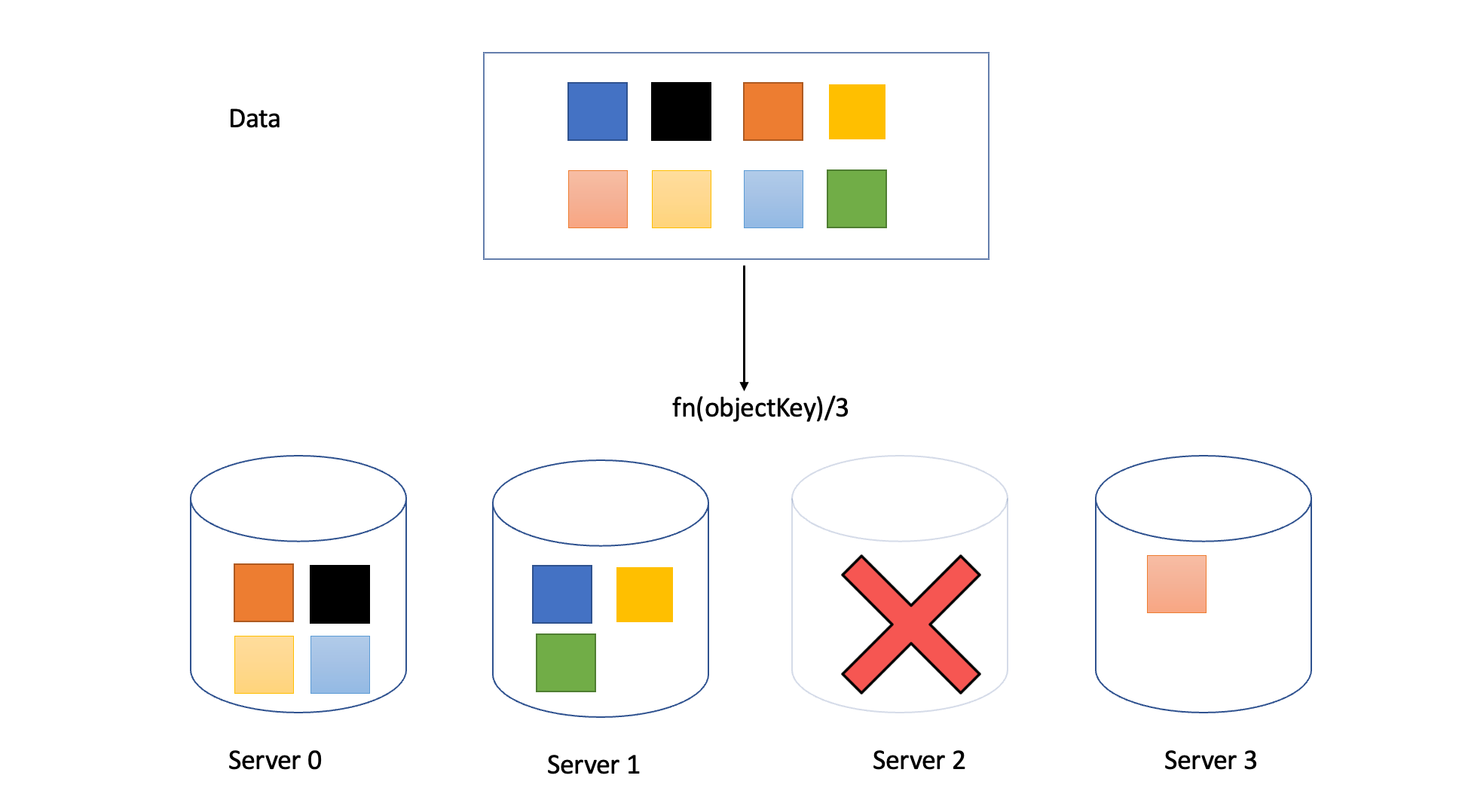
A redistribution will occur but with a new modulus of 3 (Available servers, or 5 in case a new server is added) this will change the allocation for almost all of the object keys causing lot of misses on the server in terms of data lookup.
Consistent Hashing
Consistent hashing is a technique used to distribute data across multiple nodes in a distributed system. Unlike traditional hashing algorithms, which map data to a fixed number of buckets or nodes, consistent hashing provides a dynamic and scalable approach. It allows for the addition or removal of nodes with minimal redistribution of data, thus ensuring minimal disruption to the system.
At its core, consistent hashing relies on the concept of a hash ring. Imagine a circular ring with a large number of equally spaced points around its circumference, representing all possible hash values. Each node in the system is also assigned a point on this ring based on its unique identifier or hash value.
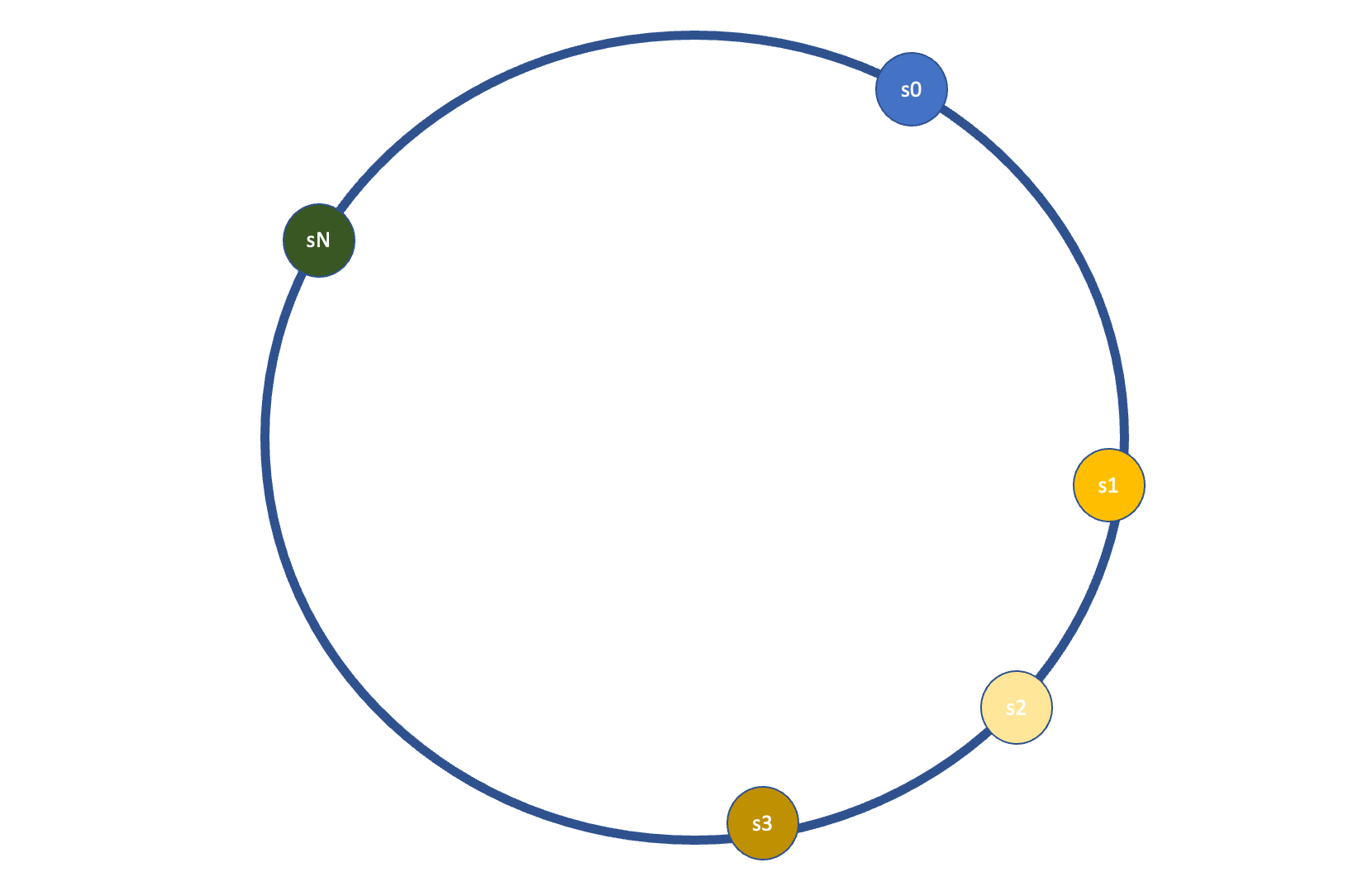
Data Distribution
When data enters the system, it is hashed to generate a hash value. The data is then placed on the ring at the point closest to its hash value. To determine which node will be responsible for storing the data, we start from the data's position on the ring and traverse clockwise or anti-clockwise (whichever convention is decided upon) until we encounter the first node. That node becomes the owner of the data
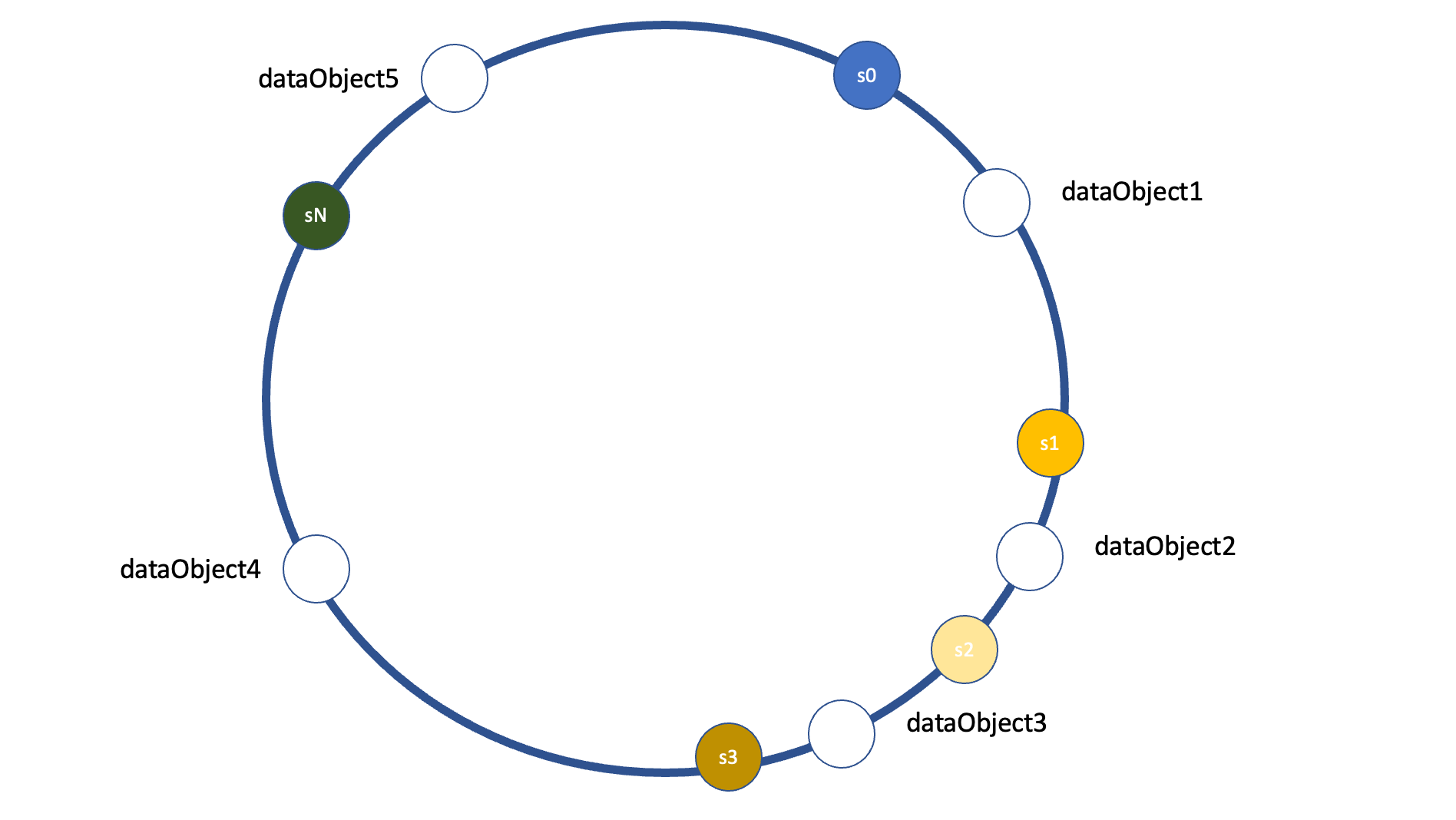
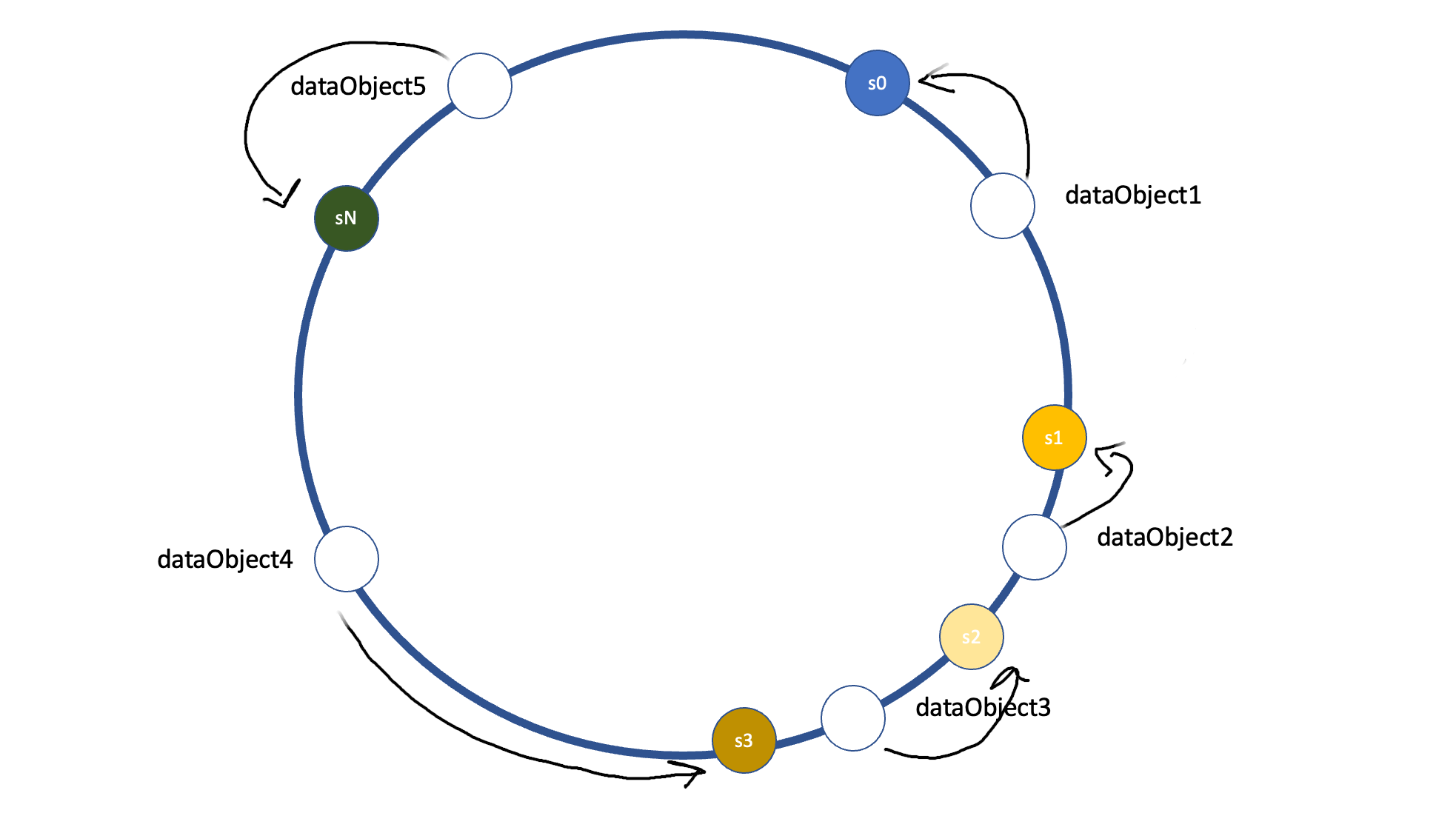
Node Addition and Removal
One of the key advantages of consistent hashing is its ability to handle node additions and removals gracefully. When a new node joins the system, it is assigned a point on the ring. Data that previously belonged to neighboring nodes gets evenly redistributed, while data far away from the new node remains unaffected. Similarly, when a node leaves the system, its data is evenly distributed among its neighboring nodes, without affecting the rest of the data.
Load Balancing
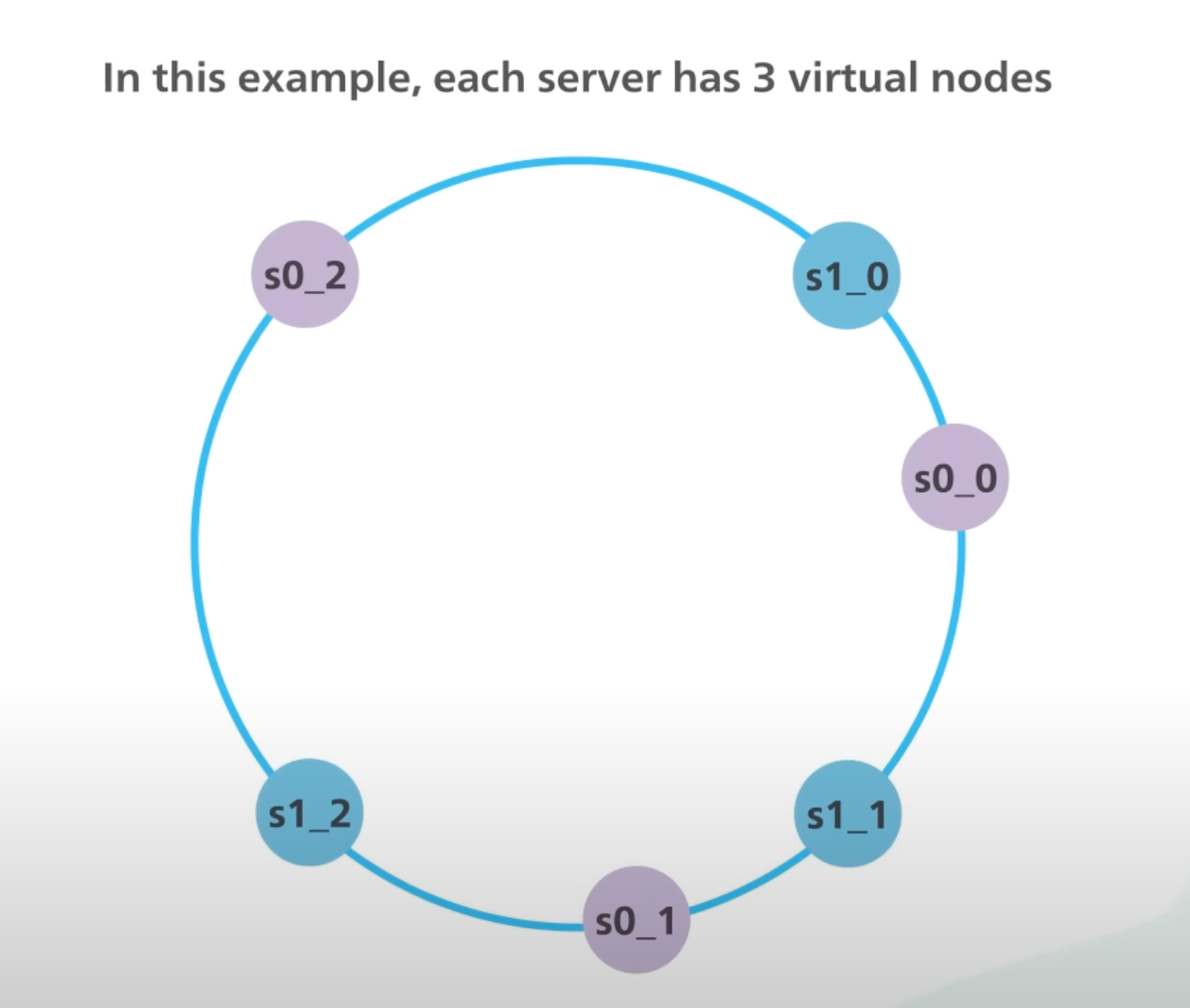
Consistent hashing also provides inherent load balancing capabilities. The concept of virtual nodes marks single server at multiple points on the circle, a server with 2X more power has 2X more virtual nodes, hence making sure that server with higher power gets more load. As nodes are added or removed, the data redistribution ensures that the load is evenly distributed among the available nodes. This prevents hotspots and ensures efficient utilization of system resources.
Fault Tolerance
Another significant advantage of consistent hashing is its fault tolerance. Since data is distributed across multiple nodes, if one node fails or is taken offline, only a portion of the data is affected. The remaining nodes can still serve the data that belongs to them, ensuring the system remains operational.
Conclusion
Consistent hashing stands as a powerful technique that addresses the challenges of data distribution, load balancing, fault tolerance, and dynamic cluster management in distributed systems. Its dynamic and scalable nature makes it an ideal choice for large-scale applications, allowing for seamless scaling and efficient resource allocation. Database systems like DynamoDB and Cassandra use Consistent Hashing to power data distribution.
By providing an elegant solution for adding and removing nodes with minimal data redistribution, consistent hashing ensures the system remains robust and fault-tolerant. Its inherent load balancing capabilities prevent hotspots and maximize resource utilization, resulting in optimal performance.
Explain to me like I am 5
Imagine you have a magical circle with different sections, and you have a box full of delicious chocolates that you want to share with your friends. But you want to make sure everyone gets a fair share without any arguments.
So, you use the magical circle to divide the chocolates. Each friend has their own special section on the circle. When a new chocolate arrives, you look at its special pattern or wrapper and put it in the section that matches it the best. That chocolate belongs to that friend.
If a new friend wants to join the chocolate party, you add a new section to the magical circle just for them. Each friend still has their own unique section, so they know exactly where their chocolates will be.
If a friend needs to leave the party, you remove their section from the magical circle, and their chocolates get distributed evenly among the other friends. This way, everyone still gets a fair amount of chocolates.
Consistent hashing is like using a magical circle to divide and share chocolates among friends, making sure everyone has their own chocolates and nobody feels left out.