System Design - CAP Theorem


Preface
Reason why I love my work is it's always unsettling but in a nice way. I don't wan't to learn a thing for couple of years and then keep repeating it for rest of my career and thankfully the software development world demands growth every single day. In my career of over 8 years I have worked on simple and complex applications solving problems for the users. From Web Development to AI it has been quite a ride. But for the past couple of years I have spent dedicated time learning System Design to scale applications. It's one thing to build something that just works and another to build it in a way that it scales with time. The ongoing demand of bug fixes and features can still be dealt with in an application if you have a good tech team and a sane product owner. But the most difficult yet desirable problem to solve is, how to make the system scalable. More often than not the demand for application is unanticipated or undervalued and things start to break when there is a sudden surge. Our job as technology architects is to build a system design which scales with time and load. Think of it as the blueprint or the dotted lines for your tech team to connect. The more detailed is the planning the better is the implementation.
To scale our systems with load and demand the first thing we will need is scaling our servers. We have two options to begin with
Vertical Scaling is our traditional way where we increase the horsepower of our existing server, by increasing the RAM and CPU. This kind of scaling generally requires a downtime and is good at times where your task is resource intensive. Ex- Running a machine learning task in a pipeline. Though advancement in parallel processing systems have enabled us to scale horizontally with minimum to zero downtime.
Horizontal Scaling, is where the power of distributed computing comes in, we spin parallel servers of same or varying capacity and distribute the incoming load. Tasks which are demand heavy, like serving many requests at the same time are perfect candidates for horizontal scaling. Though horizontal scaled servers and database come with various challenges. Keeping data consistent throughout the distributed node is one such challenge.
Computer scientist Eric Brewer laid down a theorem commonly known as CAP theorem, where C is consistency, A is availability and P is Partition Tolerance. The CAP theorem states that at any point of time any distributed database system can only achieve two of the three between Consistency, Availability and Partition Tolerance.
CAP theorem works as a guiding north star when you are designing your system.
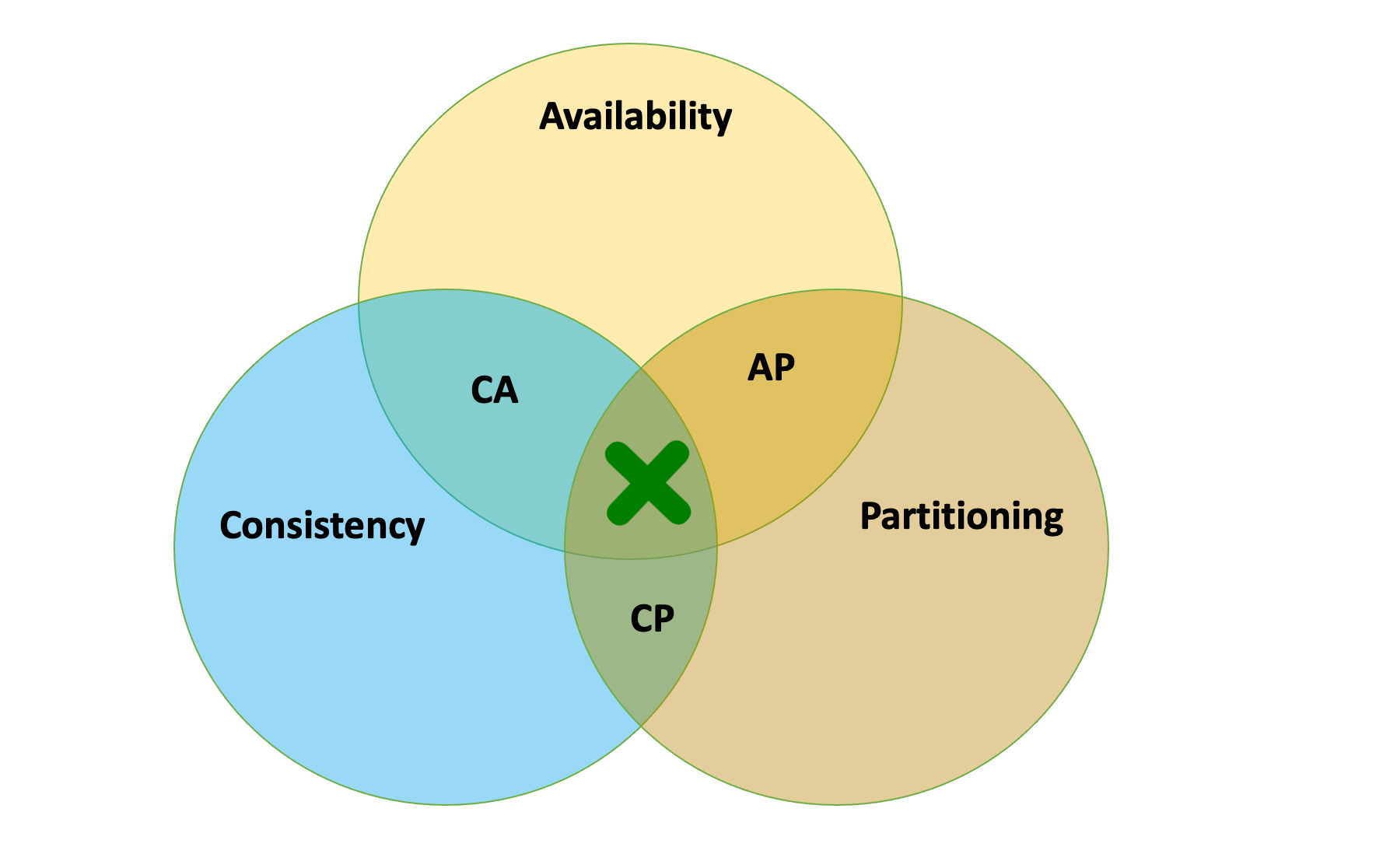
Highly Consistent system is where all clients see the same data at the same time irrespective of which node they connect to or what CRUD operations are performed. To make a system consistent we make sure that a write operations is marked as successful only after is written to all instances.
Highly Available system is where the client always gets a response whether it's a success or failure. So for this the system has to remain live 100 percent of time irrespective of state of individual nodes in the distributed system.
Partition Tolerant system continues to perform as expected irrespective of N number of network delays between nodes. Such system should continue working even after network failures as data is replicated across nodes to handle any network failure and outage. Modern systems demand Partition Tolerance by design and hence we need to understand the business requirement and choose between Highly Consistent or Highly Available system with Partition Tolerance. i.e CP or AP.
Consistency over Availability
In systems like finance (Trading , banking) or booking (Movie/flight) it's more important for the users to see consistent data. It's ok for the client to be not available at times and only show data after it's consistent. Ex- Bank balance of a user should be same across all responses irrespective of which node is replying.
So the system is consistent and becomes eventually available
Availability over Consistency
In system like social media and video streaming, it's more important to be available for the user all the time than show all the users the exact data. The count of likes, comments or views may be different for a user and become eventually consistent but being available for the user is more important. Ex- Live streaming of a football match, all requests from users must be able returned, being available for users, though the video stream maybe delayed by seconds based on bandwidth.
So the system is always available and tries to become eventually consistent.
This is the beginning of a series of posts I will be writing to discuss my learning of System Design. Stay tuned for more.